Damn impressive speed improvements. I want to see this up against a Netezza.EMC's Pivotal Initiative division made a big splash last week with the launch of its Pivotal HD distribution of Hadoop. This is not a normal Hadoop distribution, but one that takes the parallel guts of the Greenplum database and reworks them to transform the Hadoop Distributed File System (HDFS) into something that speaks perfectly fluent SQL.
As discussed previously, Pivotal HD will incorporate Project Hawq, an SQL database layer that rides atop of HDFS rather than trying to replace it with a NoSQL data store.
How does this Hawq layer work, and just how fast is it? El Reg attended a presentation where Gavin Sherry, the Greenplum database chief architect who spearheaded the development of the Hawq database layer, took us through some of the details, while Josh Klahr, product manager for Pivotal HD, showed off EMC's latest Hadoop distro and the Hawq add-on.
Sherry started out by reminding everyone that Hawq speaks ANSI-compliant SQL, and any version of SQL at that. That means any kind of graphical tool, such as Tableau, can ride atop Hawq, as can EMC's own Chorus management tool and query dashboard. You can also, as Sherry pointed out, poke it with JDBC or ODBC queries, call it from Ruby, Python, Scala, Clojure, or other languages, or attack it from within an SQL console, as Sherry himself did during a demonstration.
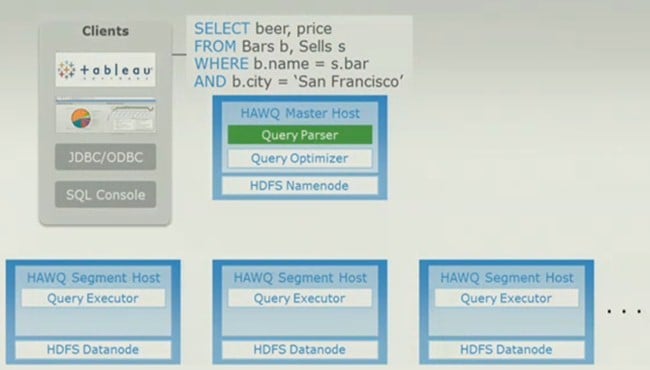
It also starts with an SQL query that is run through the Hawq parser, like so:
An SQL query gets parsed by the Hawq database layer for HDFS
"One that query comes in, we parse it and generate a parse tree, and I am getting a little bit nerdy here," explains Sherry. "The something very special happens. We take that parse tree, and we take metadata from our universal catalog service. We take a cost model that actually reflects the underlying Hadoop cluster. It understands the performance of the storage, it understands the cost of accessing this data over that data, or data in one particular order or another. And then it sends a resource model, and combined it generates a query execution plan."
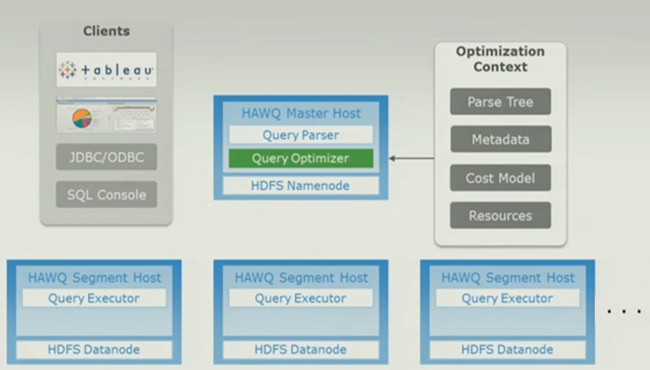
Like this:
The SQL query gets put through a parallel optimizer that understands HDFS
"There is something incredibly important about this process," Sherry continued, "and it has taken 40 years of computer science research to get to what we have here today. That execution plan is the optimal execution plan for utilization of the Hadoop cluster. This cost model-based optimization is really something rare, and in fact, no one else in the industry working with Hadoop, working with query engines on top of Hadoop, has anything like this."
In this particular execution plan, Sherry noted, it is just a two-way join of database tables, and this is a relatively simple task for the Hawq query optimizer. "We are already doing 20-, 30-, and 60-way joins with this optimizer," boasted Sherry.
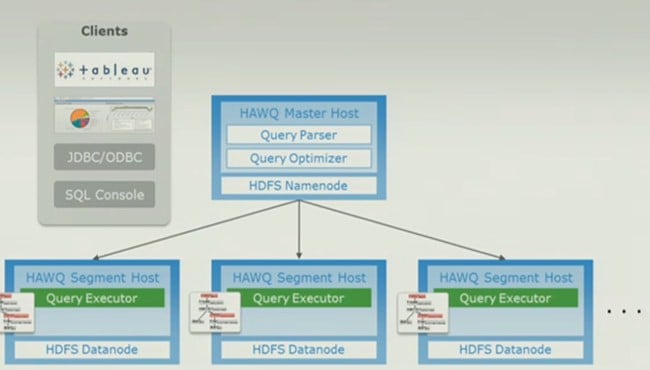
The query executor uses the HDFS NameNode to pass work to Hawq database segments
The secret to Hawq, Sherry said, was that the database layer has dynamic pipelining, which is the combination of a bunch of different Greenplum technologies that have been built for the parallel relational database (a derivative of PostgreSQL) that Greenplum created when it was a standalone company a decade ago.
The dynamic pipeline is a job scheduler for queries (separate from the NameNode and the JobTracker in Hadoop) that can schedule queries in the most optimal way.
After the queries are executed on the appropriate data chunks under the direction of the Hadoop NameNode, they stream back to the NameNode and the results are streamed back to whatever bit of software was doing the SQL query.
This dynamic pipeline is what makes Hawq perform 10X to 600X times faster running SQL queries compared to using something like Hive running atop HDFS. And, these performance improvements are what turn Hadoop from a batch system into an interactive one.
Then, in a live demonstration, Klahr took a 60-node Hadoop cluster equipped with a retail establishment's data with 1 billion rows of data and sorted that customer information into two buckets, male and female. Using HDFS and the Hive data warehouse and its SQL-like HiveQL, this query took more than an hour. On the same cluster running Hawq on top of it, this sort took around 13 seconds on stage.
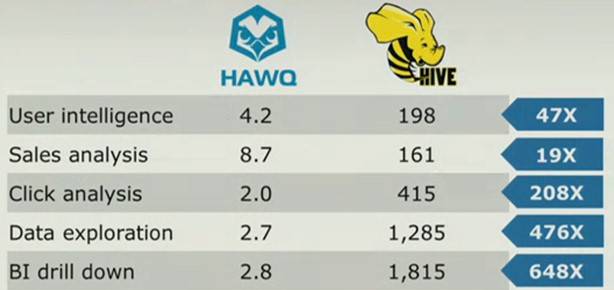
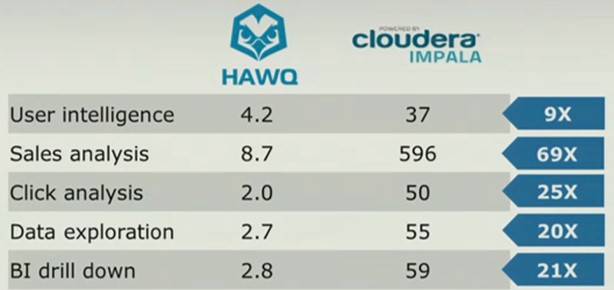
Here's how the Hawq database services running atop Pivotal HD stack up to the HDFS-Hive combo on a variety of benchmarks on the same 60-node Hadoop cluster. Queries that might take hours or even more than a day in Hive can be done in minutes in Hawq:
How Hawq stacks up to Hive on a 60-node cluster doing various queries
Hive converts those HiveQL queries into MapReduce routines and runs then against data stored inside of HDFS, but the Project Impala database layer from commercial Hadoop distie Cloudera gets MapReduce out of the way and puts a database execution engine on each one of the Hadoop nodes. It then parallelizes the queries, much as Hawq is doing. But, as you can see, Greenplum knows a thing or two about parallel queries that Cloudera apparently has not (yet) learned:
Hawq outruns Cloudera's Impala on SQL queries – at least when EMC runs the tests
"Something that may take you an hour in Impala may take you a minute in Hawq," proclaims Klahr.
Cloudera announced Impala last October and it is expected to be generally available in a month or two.
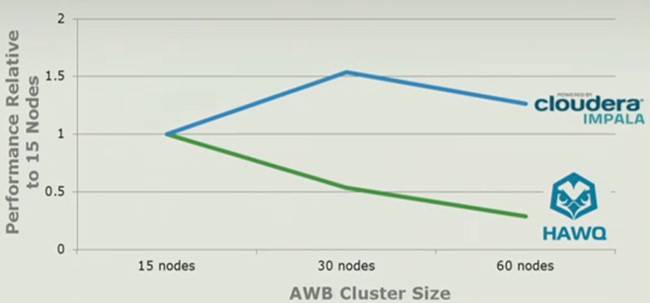
The other thing that EMC thinks it can do better than the HDFS-Impala combination is scale horizontally. Take a look at this comparison:
EMC says that its Hawq database for HDFS will scale better than Cloudera's Impala
The bump up and then bump down for the Impala parallel query run as nodes are added to the cluster is a bit odd, as you would expect to see queries get faster as more and more nodes are added to the cluster - as happened with the Hawq cluster when nodes were added. These tests are using the exact same data set - and for setups with 15, 30, and 60 nodes. The whole purpose of Hadoop, explained Sherry, was that if you double the nodes you should be able to do the job twice as quickly.
The fact that Cloudera's Impala actually slowed down when it moved up from 15 to 30 nodes "just demonstrates the challenges of dealing with these queries in a parallel environment," said Klahr. ®
EMC touts screeching Hawq SQL performance for Hadoop
Moderator: Moderators
-
Sabre

- DCAWD Founding Member
- Posts: 21432
- Joined: Wed Aug 11, 2004 8:00 pm
- Location: Springfield, VA
- Contact:
EMC touts screeching Hawq SQL performance for Hadoop
The Reg
Sabre (Julian)

92.5% Stock 04 STI
Good choice putting $4,000 rims on your 1990 Honda Civic. That's like Betty White going out and getting her tits done.
92.5% Stock 04 STI
Good choice putting $4,000 rims on your 1990 Honda Civic. That's like Betty White going out and getting her tits done.